

ESG Data
Sustainability Business Analytics
Sustainability

I want to start with something that I suspect a lot of people working in sustainability will recognise immediately.
You are in the middle of your week. You have a reporting deadline, a supplier chasing you for data, and somewhere in between, a message arrives asking for the energy consumption figures from last quarter. Compared to the year before. Broken down by site.
You open Excel. You find the tab. You apply the filters. You copy the numbers somewhere else. You format them. You double-check them because there is no version history, and you are not entirely sure if this is the file you updated last month or the one before. You send it.
Forty minutes. Gone.
That cycle — that same cycle, repeated across dozens of requests, across every month — is what eventually pushed me to ask a question that changed how I approach sustainability work entirely: why are we still managing ESG data like this?
I want to be precise here, because this is not a post about Excel being bad. Excel is an extraordinary tool for the right job. The problem is that ESG data management is not that job, and most sustainability teams are using it anyway because there has not been an obvious alternative that does not require a large budget or an IT department.
The issues I kept running into were structural. No version history. No permissions model. No audit trail. No way of knowing whether the number in a cell had been touched since it was entered, or by whom, or why. When you are working with data that will eventually be disclosed, audited, and compared against regulatory standards, those are not minor inconveniences — they are fundamental risks.
But beyond compliance, there was a more basic frustration: you are a slave to how Excel thinks. The data is shaped by the tool, not by what the data actually needs to be. Pivot tables, manual filters, and copy-paste between sheets — every time you do that, you are introducing friction and potential error into information that should be clean, structured, and queryable.
The moment I moved that data into a proper database — in this case DuckDB — something shifted. Suddenly, the data was just data. Structured, consistent, queryable. And more importantly, it was the foundation of something that Excel could never be: a real ESG data infrastructure with room to grow.
Once your data lives in a proper database, the next steps become possible: automated pipelines that pull from data sources directly, real-time quality checks, and version-controlled transformations. The kind of ESG data infrastructure that does not just store numbers but actually supports how your organisation makes decisions. None of that starts from Excel. It starts from a database.
I started studying Data Science and Data Engineering about a year ago. Not because I wanted to change careers, but because I kept hitting a ceiling in sustainability work where I could see what needed to happen technically and lacked the language to make it happen myself.
That study confirmed something I had suspected for a while: the gap in most sustainability teams is not ambition or knowledge — it is data infrastructure. The organisations that are genuinely ahead on ESG reporting are not the ones with the most sophisticated AI tools. They are the ones that did the unglamorous work of centralising their data, building pipelines that reduce manual input, and creating systems where the data can actually be trusted.
According to research on ESG data management maturity, only around 15% of companies currently have solid, automated ESG data capabilities. The rest are still somewhere in the spreadsheet world, doing manually what could and should be automated.
The regulatory pressure from CSRD and similar frameworks is making this increasingly untenable. When an auditor asks you to demonstrate data lineage, and you have to explain that your source of truth is a shared Excel file with no change log, that is not a data problem. It is an infrastructure problem. And it has a solution.
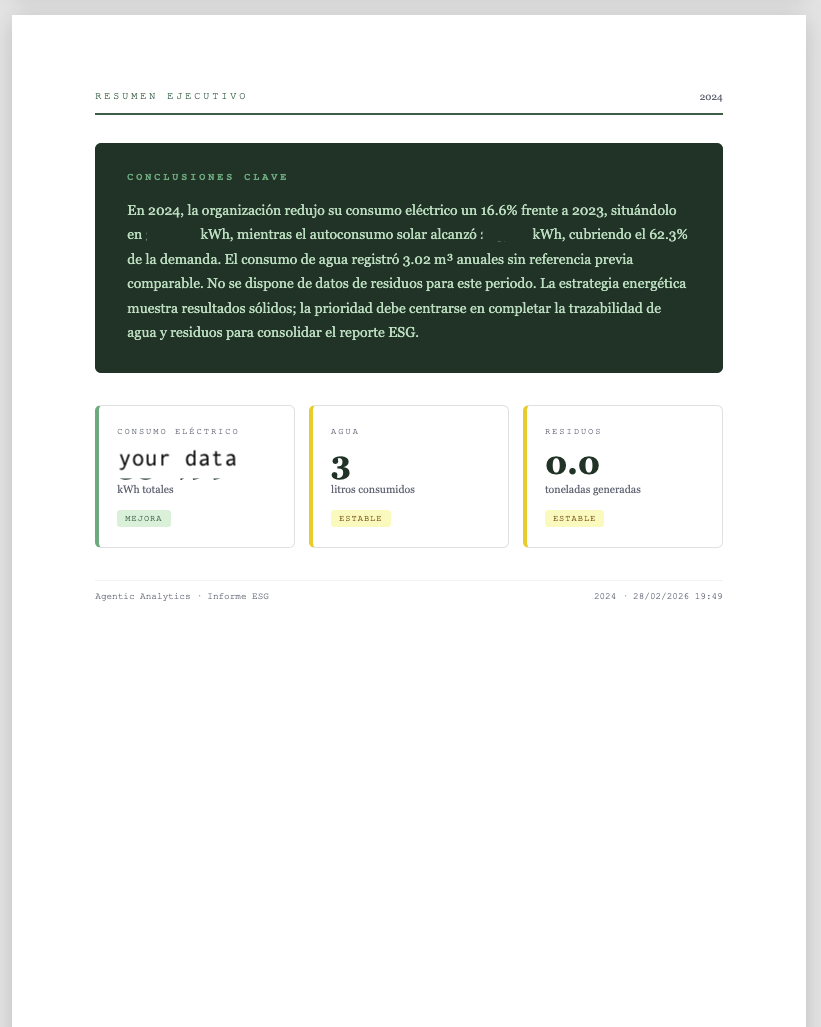
A few weeks ago, I built a working prototype that connects directly to a real environmental database — electricity consumption, water usage, waste data, renewable self-generation — and allows anyone you allows to query that data in plain English, extract structured KPIs automatically, and generate a formatted sustainability report with a single click.
I am not going to spend a lot of time describing the technical architecture here, partly because it is documented in detail on GitHub, and partly because the technical implementation is not really the point. Anyway, I'm summarising it below:
Agentic Analytics ESG is a two-agent system that turns raw environmental data stored in a DuckDB database into natural-language analysis and structured PDF sustainability reports — entirely through conversational AI.
It was designed by a Data Scientist and Sustainability Specialist with the following philosophy: the most valuable skill is not writing code, it is understanding what a business actually needs and knowing when a simple solution is better than a sophisticated one.
This prototype demonstrates that a non-engineering profile can reason about agentic system design, define tool boundaries, specify data contracts between agents, and deliver a working end-to-end product — without writing a single line of code manually.Here it's an example of how this works as a Chatbot or template this code produces.
The point is that it saves roughly 10 hours per month in manual data extraction and reporting work. Hours that currently go into opening files, applying filters, reformatting outputs, and re-answering the same questions about the same data. Hours that could go into actual analysis, actual strategy, and actual sustainability work.
I am also not going to pretend this prototype is production-ready, because it is not. It has limitations, which I have been fully transparent about in the documentation. It is a proof of concept, not a finished product. But it demonstrates something real: that the technical barrier to building this kind of tool is now low enough that a sustainability professional with data skills can do it — and that when you do, the value is immediate and tangible.
One of the features I built into the system is a carbon footprint tracker for every query the system runs.
Every question asked, every report generated — the system calculates the CO₂ equivalent of that operation based on the tokens consumed, published energy efficiency data, and grid carbon intensity. It is displayed in the interface, broken down by phase.
I included this because it felt dishonest not to. If you are building tools in the sustainability space and you are not thinking about the resource cost of those tools, you have lost something important. The numbers in this case are very small. But the habit of asking the question is not.
A large part of my previous writing has been about being sceptical of the AI-for-everything narrative in sustainability. I still hold that position.
Most ESG data problems are solved by better data infrastructure, cleaner pipelines, and more honest governance — not by AI. AI comes after those foundations are in place, not instead of them. If you are still manually collecting utility invoices in spreadsheets, an AI assistant is not your next step. A database is.
This project uses AI. But it uses it in a specific, bounded way — to make structured data queryable in natural language, and to generate report narratives from structured inputs. It does not use AI to replace thinking. It uses it to remove friction.
That distinction matters to me, and I think it should matter to anyone evaluating technology for sustainability work.
Studying Data Science and Data Engineering while working in sustainability has been one of the more uncomfortable and useful things I have done professionally. Uncomfortable because it forces you to confront how much of what we do manually could be done better. Useful because once you can see that, you cannot un-see it.
The skill I am most interested in developing — and the one I think the sustainability sector needs far more of — is the ability to move between domain knowledge and technical possibility. Not to become an engineer. Not to abandon the environmental focus. But to be fluent enough in both languages to identify where the gap is, scope a solution that actually fits the problem, and build it without making it more complicated than it needs to be.
That is what this project is, at its core. A small, honest attempt to close a gap that I could see and could not stop seeing.
Full project and documentation: github.com/Daaviid99/agentic-analytics-sustainability
